Last updated by: Les Cottrell on May 20, 2000
Of the 24, 5 came in a short burst on December 16th between 04:00 and 10:00 (PST) all from sarka.fzu.cz. 4 more occurences to ftp.physics.carleton.ca happened on December 10,11,12 and 15. 3 Other sites (ntp.dnai.com, mnhepw.hep.umn.edu, uae6.ciemat.es) had 3 occurences each, there were two occurences to fnal.fnal.gov, and 4 other sites had one incident each.
In all cases the out-of-order packet was due to an extraordinarily long response time. Some were long for all the pings, some had just the out-of-order ping taking up to 68 times as long to return as the minimum time for that sample.
The standard ping process, for most systems that we monitor with, stops when it has received the number of pings sent. We discard the 0th ping since it is regarded as "priming the pump". So in the above case we record 5 pings sent (we don't count the ping with sequence 0) and 6 received, which results in zero packet loss. The pathology of pings received being > pings sent probably needs an alert to be raised.
This is just a fact of life, so we avoid pinging routers when possible.
3cottrell@flora01:~>bin/pingroute.pl -s 1473 -c 5 www.cern.ch
Architecture=SUN5, commands=traceroute -q 1 and ping -s node 1473 5, pingroute.pl version=1.4, 5/16/00, debug=1
pingroute.pl version 1.4, 5/16/00 using traceroute to get nodes in route from flora01 to www.cern.ch
traceroute: Warning: ckecksums disabled
traceroute to webr.cern.ch (137.138.28.228), 30 hops max, 40 byte packets
pingroute.pl version 1.4, 5/16/00 found 12 hops in route from flora01 to www.cern.ch
1 RTR-CORE1.SLAC.Stanford.EDU (134.79.19.2) 4.545 ms
2 RTR-CGB6.SLAC.Stanford.EDU (134.79.135.6) 0.945 ms
3 RTR-DMZ.SLAC.Stanford.EDU (134.79.111.4) 1.071 ms
4 ESNET-A-GATEWAY.SLAC.Stanford.EDU (192.68.191.18) 0.820 ms
5 chicago1-atms.es.net (134.55.24.17) 56.938 ms
6 206.220.243.32 (206.220.243.32) 59.278 ms
7 cernh9-s5-0.cern.ch (192.65.184.142) 169.370 ms
8 cgate2.cern.ch (192.65.185.1) 169.680 ms
9 cgate1-dmz.cern.ch (192.65.184.65) 171.845 ms
10 b513-b-rca86-1-gb0.cern.ch (128.141.211.1) 169.180 ms
11 b513-c-rca86-1-bb1.cern.ch (194.12.131.6) 171.702 ms
12 webr.cern.ch (137.138.28.228) 171.861 ms
Wrote 12 addresses to /tmp/pingaddr, now ping each address 5 times from flora01
pings/node=5 100 byte packets 1473 byte packets
NODE %loss min max avg %loss min max avg from flora01
134.79.19.2 RTR-CORE1.SLAC.STANFORD.EDU 0% 0.0 0.0 0.0 0% 1.0 1.0 1.0 Sat May 20 17:36:47 PDT 2000
134.79.135.6 RTR-CGB6.SLAC.STANFORD.EDU 0% 0.0 1.0 0.0 100% 0.0 0.0 0.0 Sat May 20 17:36:55 PDT 2000
134.79.111.4 RTR-DMZ.SLAC.STANFORD.EDU 0% 1.0 1.0 1.0 100% 0.0 0.0 0.0 Sat May 20 17:37:13 PDT 2000
192.68.191.18 ESNET-A-GATEWAY.SLAC.STANFORD. 0% 0.0 1.0 0.0 0% 2.0 2.0 2.0 Sat May 20 17:37:31 PDT 2000
134.55.24.17 CHICAGO1-ATMS.ES.NET 0% 57.0 64.0 58.0 0% 59.0 62.0 59.0 Sat May 20 17:37:39 PDT 2000
206.220.243.32 206.220.243.32 0% 58.0 62.0 59.0 100% 0.0 0.0 0.0 Sat May 20 17:37:47 PDT 2000
192.65.184.142 CERNH9-S5-0.CERN.CH 0% 168.0 170.0 169.0 100% 0.0 0.0 0.0 Sat May 20 17:38:06 PDT 2000
192.65.185.1 CGATE2.CERN.CH 0% 169.0 170.0 169.0 100% 0.0 0.0 0.0 Sat May 20 17:38:24 PDT 2000
192.65.184.65 CGATE1-DMZ.CERN.CH 0% 169.0 171.0 169.0 100% 0.0 0.0 0.0 Sat May 20 17:38:42 PDT 2000
128.141.211.1 B513-B-RCA86-1-GB0.CERN.CH 0% 169.0 176.0 171.0 0% 175.0 175.0 175.0 Sat May 20 17:39:01 PDT 2000
194.12.131.6 B513-C-RCA86-1-BB1.CERN.CH 0% 169.0 172.0 170.0 0% 175.0 178.0 176.0 Sat May 20 17:39:09 PDT 2000
137.138.28.228 WEBR.CERN.CH 0% 169.0 172.0 170.0 0% 175.0 176.0 175.0 Sat May 20 17:39:17 PDT 2000
It is seen that routers rtr-core1.slac.stanford.edu (a Cisco 8500),
esnet-a-gateway.slac.stanford.edu, chicago1-atms.es.net,
B513-b-rca86-1-GBO.cern.ch, B513-C-RCA86-1-BB1.CERN.CH and the
end host webr.cern.ch all correctly
repsonds to 1473 byte pings; while routers
rtr-cgb6.slac.stanford.edu and rtr-dmz.slac.stanford.edu (Cisco 7500s), 206.220.243.32,
cernh9-s5-0.cern.ch, cgate2.cern.ch and cgate1-dmz.cern.ch
see 100% loss.
Also some routers cannot correctly form and send ping packets that require fragmentation (i.e. pings longer than 1500 Bytes).
This problem has been reported to SGI. One way to get around this problem is to use a standard system for the monitoring such as a NIMI or Surveyor platform.
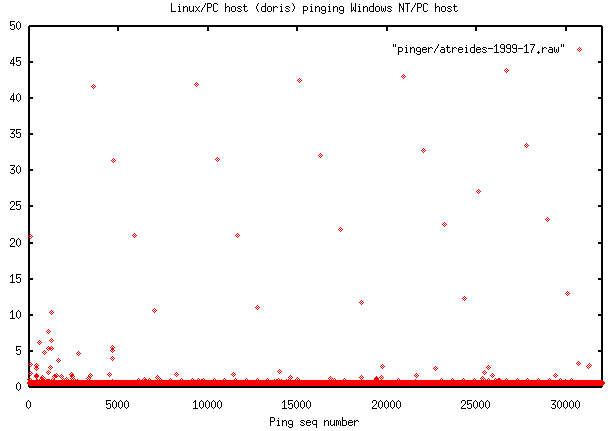
Timestampswe compared the host ping RTT with the wire RTT. For these pings there was exact agreement in the date stamp of the tcpdump and the time of the ping, and there were 23 such pings recorded. In the table below we report: the index (i) of the packet; the tcpdump round trip time (rtt), to an accuracy of 10 msec., calculated by sutracting the wire time of the echo request packet from the wire time of the corresponding echo response packet; the seconds from the start of the pings; the host ping reported sequence number; the RTT reported by the host; and the inter sequence number difference for the packets shown (i.e. dSeq(i)=Seq(i+1)-Seq(i) for i=1..22).
By default, all output lines are preceded by a timestamp. The timestamp is the current clock time in the formhh:mm:ss.frac
and is as accurate as the kernel's clock (e.g., +-10ms on a Sun-3). The timestamp reflects the time the kernel first saw the packet. No attempt is made to account for the time lag between when the ethernet interface removed the packet from the wire and when the kernel serviced the `new packet' interrupt (of course, with Sun's lousy clock resolution this time lag is negligible.))
i rtt secs. Sequence # Host RTT dSeq 1 0.03 21933 icmp_seq=21933 time=39.0 ms 1141 2 0.02 23074 icmp_seq=23074 time=29.1 ms 1141 3 0.01 24215 icmp_seq=24215 time=18.3 ms 2342 4 0.05 26557 icmp_seq=26557 time=50.2 ms 1141 5 0.03 27698 icmp_seq=27698 time=39.3 ms 1141 6 0.02 28839 icmp_seq=28839 time=29.4 ms 1141 7 0.01 29980 icmp_seq=29980 time=18.6 ms 2342 8 0.04 32322 icmp_seq=32322 time=50.0 ms 1141 9 0.04 33463 icmp_seq=33463 time=41.1 ms 2282 10 0.02 34604 icmp_seq=34604 time=29.3 ms 3483 11 0.01 35745 icmp_seq=35745 time=18.8 ms 2342 12 0.05 38087 icmp_seq=38087 time=50.4 ms 1141 13 0.04 39228 icmp_seq=39228 time=40.6 ms 1141 14 0.02 40369 icmp_seq=40369 time=29.8 ms 1141 15 0.01 41510 icmp_seq=41510 time=19.5 ms 1269 16 0.02 42779 icmp_seq=42779 time=21.0 ms 360 17 0.01 43139 icmp_seq=43139 time=19.6 ms 3483 18 0.04 46622 icmp_seq=46622 time=41.2 ms 1141 19 0.03 47763 icmp_seq=47763 time=31.0 ms 1141 20 0.02 48904 icmp_seq=48904 time=20.3 ms 3483 21 0.04 52387 icmp_seq=52387 time=41.4 ms 1141 22 0.03 53528 icmp_seq=53528 time=31.6 ms 1141 23 0.02 54669 icmp_seq=54669 time=20.9 msIt can be seen that within the resolution of our measurements, there is exact correlation in the host and wire reports for pings with RTTs of >= 10 msec. In addition a regularity in the inter sequence number differences is clearly visible. Out of the 22 differences, there are 13 with a value of 1141, 1 with 2*1141, 3 with 3483 and 3 with 2342, 1 with 360 and 1 with 1269. This would appear to indicate that the regularity is either caused by the ping responder (in this case a Windows NT host) or by the network.
Further tests (see PingER Measurement Pathology Examples) including "wire-time" measures with the ping client / requester, the ping server / responder and a NetXray sniffer (on an independent PC) all on the same shared 10 Mbps hub, showed the effect appears to be limited to one Windows NT host.
It is noteworthy that NetXray running on the WNT ping responder does not observe the longer RTTs of the pathological pings, whereas NetXray running on a separate WNT PC did see the longer RTTs. Another notable observation was that if the ping echo request comes from a Linux/PC or Windows NT/PC host, then the 16 bit ICMP sequence number embedded in the packet is written in byte reversed order, which makes reading the NetXray decoding tricky.