Library Layout
The following class diagram shows the relation of the basic interface classes:
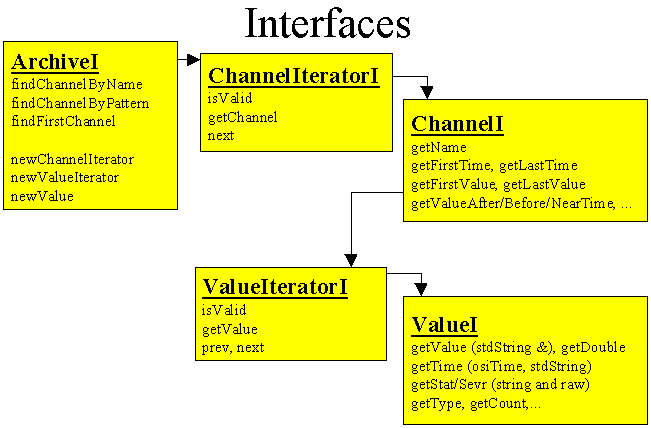
The example section is probably the most important part of this document for actual usage of the API, but you should read until then to understand what's going on.
Goals
Minimal, portable, easy to use. Pick any two.The library classes were designed to encapsulate the minimal but necessary requirements for a generic archive. The API is defined via the interface classes (purely abstract). For actual use, a derived archive like BinArchive or MultiArchive is necessary. The interface classes allow to
- Dump all values for all channels:
Ask ArchiveI to position a ChannelIteratorI on the first channel, get its first value, iterate over values, then step to next channel - Find a channel by name and dump values from ... until in
time:
Similar, using findChannelByName and not continuing with the next channel. - List channel names (maybe only those matching a pattern)
and available time ranges for each channel
(Note that this is not easy in some storage formats but I'd still like to require it because a browser tool should be able to display this information) - For each value, allow access to the value, status, time stamp as strings for easy display as well as access to the raw type, value, time stamp as common to EPICS tools.
Since the ChannelIterator for example might have to know these details, the BinChannelIterator is likely different from a SQLChannelIterator. So the user of the API has to pick the appropriate implementation of the ChannelIterator, ValueIterator etc.? This would require code changes all over the place when switching to a different archive format.
Instead, a Factory pattern is used: After creating the specific Archive class like a BinArchive, MultiArchive, ..., the remaining classes are generated from this. Ideally only the abstract interface pointers to "a ValueI" are used, not the underlying "BinValue" or "SDDSValue" or ...
They also allow no access to the file names that are actually used, how the values are organized in memory etc. to keep the API portable. To make this easy to use, a generic Iterator pattern is applied: When asking the ArchiveI for a channel, a ChannelIteratorI is returned that points to the current Channel. When asking a ChannelI for a value after time x, a ValueIteratorI is provided that can then be positioned on the next or previous value.
There is no call "get all channel names". Nothing is said about the order of channels when iterating over them. This would be data storage specific and is really not necesary:
A shell tool doesn't care, a GUI tool will usually put the channel names one by one in a list box, and for most OS this listbox has a built-in "alphabetic order" option.
The ValueI does allow access to the raw dbr_time_xxx values and control information in addition to helpers for GUI tools, i.e. string representations and Double values for plotting. This raw data access was included because in an EPICS system some tools might need to look at the original EPICS ChannelAccess data.
Examples
Examples of using these basic interfaces:List all channel names, dump all values:
ArchiveI *archive = new BinArchive ("/home/me/tests/freq_directory");
ChannelIteratorI *channels = archive->newChannelIterator();
ValueIteratorI *values = archive->newValueIterator();
stdString tim, val, sta;
archive->findFirstChannel (channels);
while (channels->isValid())
{
cout << channels->getChannel()->getName() <<
":\n";
channels->getChannel()->getFirstValue (values);
while (values->isValid())
{
values->getValue ()->getValue (val);
values->getValue ()->getTime (tim);
values->getValue ()->getStatus (sta);
cout << tim << "\t"
<< val << "\t" << sta << "\n";
values->next();
}
channels->next();
}
delete values;
delete channels;
delete archive;
Please note that only the first line needs changes when switching from a BinArchive to e.g. a MultiArchive. The pointer handling looks awkward, though. This is why "Smart Pointer" classes Archive, ChannelIterator and ValueIterator (without the trainling "I") were introduced. Most important, they
- wrap the interface class pointers, automatically calling "delete"
- overload the bool cast with a isValid() call
- overload the ++, -- operators with next/prev calls
- overload the *, -> operators to access the Channel/Value of the iterator.
Using those, the above code looks like this:
Archive
archive (new BinArchive
("/home/me/tests/freq_directory"));
ChannelIterator channels (archive);
ValueIterator values (archive);
for (archive.findFirstChannel (channels); channels; ++channels)
{
cout << channels->getName() << ":\n";
for (channels->getFirstValue (values); values; ++values)
cout *values;
}
The Class index has a more detailed description of the individual methods as well as some more examples. It is generated from the header files and contains those portions of the API that are considered to remain as opposed to helper functions that might change.
Support for new Formats
To keep this API, support for new formats has to be derived from the interface classes. A new XX format (RDB, a specific SDDS layout, ...) has to implement- XXArchive
- XXChannelIterator, XXChannel
- XXValueIterator, XXValue
- probably: XXCtrlInfo
If it is for example impossible to iterate over channel names in the XX format, the routines XXArchive::findChannelByPattern, findFirstChannel and XXChannelIterator::next could invalidate the ChannelIterator and return false.
If you believe that some other methods required by the interface classes are not necessary and are convincing in doing so, we might consider removing them.